
As artificial intelligence (AI) continues to advance, the development of emerging architectures for LLM applications is becoming increasingly crucial. LLM applications leverage large language models (LLMs) to generate text, process data, and provide insights. Understanding these LLMs and the role of emerging architectures in optimizing their performance is essential for the future of machine learning.
Large language models (LLMs) are a valuable tool for software development, but their unique behavior requires a specific approach. A reference architecture for the LLM app stack is shared in this post, outlining common systems, tools, and design patterns used by AI startups and tech companies.
- LLMs are a powerful tool for software development.
- A reference architecture for the LLM app stack is provided in the post.
- The stack includes common systems, tools, and design patterns used by AI startups and tech companies.
- The architecture may evolve as the technology progresses but is a valuable resource for developers working with LLMs.
LLM Application Architecture.
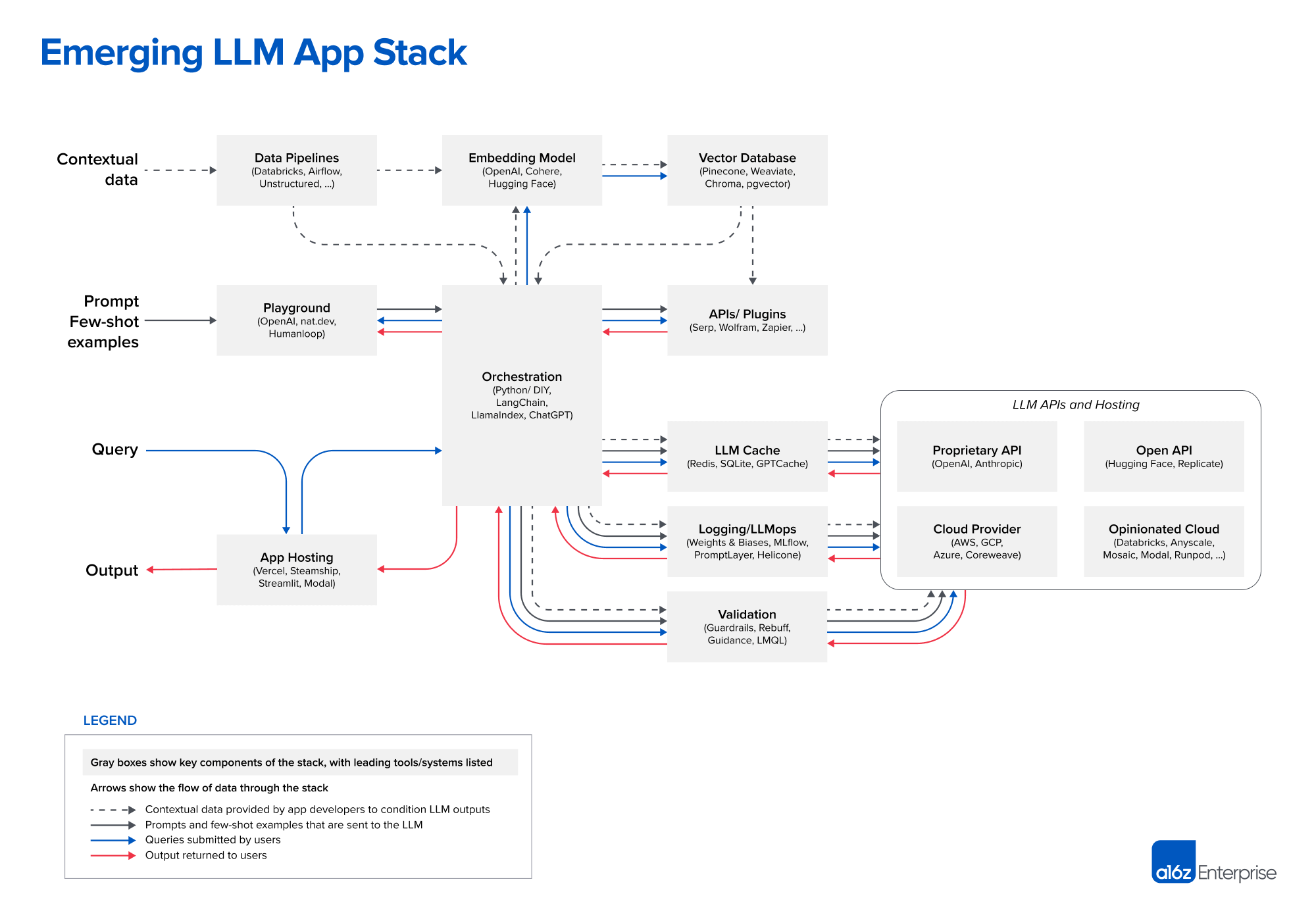
Image Source: Andreessen Horowitz
Let’s now slice through each layer of the stack and see what their role is in the LLM application architecture, why we need it, and some tools for the layer:
Data Pipelines:
- The backbone of data ingestion and transformation, connecting various data sources including connectors to ingest contextual data wherever it may reside.
- Essential for preparing and channeling data to various components in the LLM application.
- Tools: Databricks, Airflow, Unstructured
Embedding Models:
- This component transforms contextual data into a mathematical format, usually vectors.
- Critical for making sense of complex data, enabling easier storage and more efficient computations.
- Tools: OpenAI, Cohere, Hugging Face
Vector Databases:
- A specialized database designed to store and manage vector data generated by the embedding model.
- Allows for faster and more efficient querying, essential for LLM applications that require real-time data retrieval like chatbots.
- Tools: Pinecone, Weaviate, ChromaDB, pgvector
Playground:
An environment where you can iterate and test your AI prompts.
Vital for fine-tuning and testing LLM prompts before they are embedded in the app, ensuring optimal performance.
Tools: OpenAI, nat.dev, Humanloop
Orchestration:
- This layer coordinates the various components and workflows within the application.
- They abstract the details (e.g. prompt chaining; interfacing with external APIs etc.) and maintain memory across multiple LLM calls.
- Tools: Langchain, LlamaIndex, Flowise, Langflow
APIs/Plugins:
- Interfaces and extensions that allow the LLM application to interact with external tools and services.
- Enhances functionality and interoperability, enabling the app to tap into additional resources and services.
- Tools: Serp, Wolfram, Zapier
LLM Cache:
- A temporary storage area that keeps frequently accessed data readily available.
- Improves application speed and reduces latency, enhancing the user experience.
- Tools: Redis, SQLite, GPTCache
Logging/LLM Ops:
- A monitoring and logging component that keeps track of application performance and system health, essential in the era of big data and ML deployments.
- Provides essential oversight for system management, crucial for identifying and resolving issues proactively.
- Tools: Weights & Biases, MLflow, PromptLayer, Helicone
Validation:
- Frameworks that enable more effective control of the LLM app outputs.
- Ensures the reliability and integrity of the LLM application, acting as a quality check and taking corrective actions.
- Tools: Guardrails, Rebuff, Microsoft Guidance, LMQL
App Hosting:
- The platform for efficient hosting of LLM where the LLM application is deployed and made accessible to end-users.
- Necessary for scaling the application and managing user access, providing the final piece of the application infrastructure.
- Tools: Vercel, Steamship, Streamlit, Modal are emerging tools for easier deployment of LLM solutions
This is an emerging stack and we will see more changes as we progress. Many of these tools are also open-source.
Five steps to building an LLM app
Let’s simplify the steps for creating an LLM app today. 👇
1. Start by focusing on a specific problem: Choose a manageable problem for quick progress but impactful enough to impress users. For example, instead of tackling all developer issues with AI, the GitHub Copilot team concentrated on coding functions in the IDE as a starting point.
2. Selecting the appropriate LLM is crucial: While using a pre-trained model can save costs, choosing the right one is essential. Consider the following factors:
- Licensing: If you plan to commercialize your LLM app, ensure that the model you select is licensed for commercial use. You can refer to a list of open LLMs with commercial licenses to begin your search.
- Model size: LLMs vary in size from 7 to 175 billion parameters, with some smaller models like Ada having around 350 million parameters. While larger models generally offer better learning capabilities and predictions, recent advancements in smaller models are challenging this notion. Smaller models are often faster and more cost-effective, making them a viable alternative to larger models that may not be suitable for many applications.
3. Personalize the Language Model (LLM): When training an LLM, you are establishing the framework and neural networks necessary for deep learning. Customizing a pre-trained LLM involves tailoring it to specific tasks, like generating text focused on a particular topic or style. The following section will delve into techniques for this purpose. To adapt a pre-trained LLM to your requirements, you can explore in-context learning, reinforcement learning from human feedback (RLHF), or fine-tuning.
In-context learning: This also known as prompt engineering by users, entails providing the model with explicit instructions or examples at the time of inference, prompting it to deduce and produce contextually relevant outputs. This method can involve various approaches, such as offering examples, rephrasing queries, and including a sentence outlining your objective broadly.
RLHF: RLHF involves implementing a reward model for the pre-trained LLM. This model is trained to predict whether a user will accept or reject the LLM’s output. The insights from the reward model are then transferred to the pre-trained LLM, which adjusts its outputs based on user acceptance rates. RLHF offers the advantage of not necessitating supervised learning, thereby broadening the criteria for acceptable outputs. Through sufficient human feedback, the LLM can learn that if there is an 80% likelihood of user acceptance, it is suitable to generate the output. Interested in trying it out? Explore these resources, including codebases, for RLHF.
Fine-tuning: Fine-tuning involves evaluating the model’s generated output against an intended or known output. For instance, if you recognize the sentiment behind a statement like “The soup is too salty” as negative, you can feed this sentence to the model and prompt it to classify the sentiment as positive or negative. If the model incorrectly labels it as positive, you can adjust the model’s parameters and re-prompt it to correctly classify the sentiment as negative. Fine-tuning can lead to a highly tailored LLM proficient in a specific task, but it relies on supervised learning, which demands meticulous labeling and time investment. Essentially, each input sample needs an accurately labeled output for comparison with the model’s result, enabling adjustments to the model’s parameters. As mentioned earlier, RLHF offers the advantage of not requiring precise labeling.
4. Establishing the Architecture of Your App: The components essential for setting up your LLM app can be categorized into three main groups: User input, which includes a user interface (UI), an LLM, and an app hosting platform. Input enrichment and prompt construction tools encompass your data source, embedding model, vector database, prompt construction and optimization tools, and a data filter. Efficient and responsible AI tools consist of an LLM cache, an LLM content classifier or filter, and a telemetry service for evaluating your LLM app’s output.
5. Perform online assessments of your application: These assessments are labeled as “online” because they analyze the LLM’s functionality while users interact with it. For instance, GitHub Copilot’s online evaluations involve tracking the acceptance rate (the frequency of developers accepting a suggested completion) and retention rate (how frequently and extensively a developer modifies an accepted completion)
Image Source: GitHub.blog
Workflow for Executing Architecture for LLM Applications
Step 1. Data Processing / Embedding
This initial step involves processing contextual data through a data pipeline to store it in an embedding model and then into a vector database. Contextual Data: This data consists of both structured and unstructured information, such as text documents, PDFs, CSVs, and SQL tables. Data loading and transformation are typically carried out using traditional ETL tools like Databricks or Airflow. Some newer orchestration frameworks like LangChain and LlamaIndex come with built-in document loaders. There is a rising demand for data replication solutions tailored for LLM applications. Embeddings: The majority of developers utilize the OpenAI API with the text-embedding-ada-002 model. The OpenAI API is user-friendly, offers reasonably good results, and is becoming more cost-effective. For those who prefer open-source options, Hugging Face’s Sentence Transformers library is a popular choice. Various specialized embeddings for industries like finance and healthcare are currently under exploration. Vector Database: The vector database plays a vital role in the preprocessing pipeline by efficiently storing, comparing, and retrieving billions of embeddings (vectors). Pinecone is a popular choice in the market due to its cloud-hosted nature, ease of use, and features suitable for larger enterprises’ production requirements (e.g., good performance at scale, SSO, and uptime SLAs). Several open-source vector databases like Weaviate, Vespa, and Qdrant offer excellent single-node performance and can be customized for specific applications. Local vector management libraries such as Chroma and Faiss are easy to use for smaller applications and development experiments but may lack scalability as full databases. OLTP extensions like pgvector enable the integration of vector support into Postgres databases for specific use cases. Cloud offerings are shaping the vector database market, but achieving strong performance across diverse use cases in the cloud remains a challenge. Future Trends: The vector database market might witness consolidation around one or two popular systems, similar to OLTP and OLAP counterparts. With models having an increasing usable context window, embeddings, and vector databases could become more crucial in managing computational costs efficiently. Specialized embedding models trained for model relevancy might gain popularity, with vector databases designed to facilitate and optimize their usage.
Step 2. Prompt Construction / Retrieval
Strategies for prompting LLMs and integrating contextual data are becoming more intricate — and increasingly crucial for product differentiation. Orchestration frameworks like LangChain and LlamaIndex excel in abstracting many details of prompt chaining; interfacing with external APIs (including determining when an API call is necessary); retrieving contextual data from vector databases; and maintaining memory across multiple LLM calls.
Step 3. Prompt Execution / Inference
OpenAI currently leads the language model provider domain, with most developers initiating LLM app development using models like GPT-4 or GPT-4–32k. GPT-4 models are user-friendly and versatile across various domains, but fine-tuning can be challenging, and self-hosting may be costly for large-scale services. The widely used model is gpt-3.5-turbo due to its cost-effectiveness, faster response times, and efficient support for free users. However, developers may gradually transition to GPT-4 once its API becomes available. While open-source models are catching up with proprietary products, the gap is narrowing; developers can evaluate OpenAI’s sophistication in fine-tuning and prompt aspects through direct usage. Meta’s LLaMA model has set a new standard for open-source accuracy and spawned various variants like Alpaca, Falcon, and Viccuna. LLaMA 1 was licensed for research purposes only, but Meta released a true open-source LLaMa 2 model free for research and commercial use. Hosting companies like Replicate are adding tools to simplify developers’ usage of such models. To enhance response times and reduce costs, LLM caching with Redis is commonly practiced. Tools like Weights & Biases, MLFlow, PromptLayer, and Helicone are widely used for logging, tracking, and evaluating LLM outputs to facilitate rapid prompt generation, pipeline tuning, and model selection. Operational tools for verifying LLM outputs (Guardrails) or detecting prompt injection (Rebuff) are being introduced, with many of these tools recommending the use of their Python clients for LLM calls. The non-model part of LLM (everything except the model) needs to be hosted somewhere; common solutions include Vercel or major cloud providers. Steamship offers comprehensive hosting for LLM apps, providing features like orchestration (LangChain), multi-tenant data context, asynchronous tasks, vector storage, and key management. Anyscale and Modal enable developers to host both models and Python code simultaneously.
Overview of LLM Applications
Image Source: Appy Pie
LLM applications rely on large language models (LLMs) to process and generate text efficiently. These applications utilize in-context learning, fine-tuning methods, and embeddings to enhance the quality of LLM outputs. By integrating pre-trained models with contextual data, LLM applications can effectively generate responses, automate tasks, and enhance user experiences.
What can be expected in the future regarding this architecture?
The current LLM app stack is in its early stages and might undergo significant changes with advancements in underlying technology. Nonetheless, it offers a valuable point of reference for developers currently engaged with LLMs. With ongoing developments in the field, developers can anticipate the emergence of new tools and methodologies aimed at enhancing the efficiency and effectiveness of constructing LLM applications.
Cutting-edge Technologies
The LLM application stack incorporates various advanced technologies and tools, including data pipelines, embedding models, vector databases, orchestration tools, APIs/plugins, and LLM caches. Among the tools and technologies utilized in this stack are Klu.ai, Databricks, OpenAI, Pinecone, Langchain, Serp, Redis, Airflow, Cohere, Qdrant, LlamaIndex, Wolfram, SQLite, Unstructured, Hugging Face, ChromaDB, ChatGPT, GPTCache, pgvector, Logging / LLMOps, Weights & Biases, Guardrails, Vercel, AWS, MLflow, Rebuff, Anthropic, Replicate, GCP, Anyscale, Microsoft Guidance, Azure, Mosaic, LMQL, Modal, CoreWeave, Modal, RunPod.
Importance of Emerging Architectures for LLM Applications
The emergence of new architectures for large language models is revolutionizing the field of AI. These architectures, such as LangChain and design patterns like the LLM app stack, offer novel approaches to training and deploying LLMs. By exploring emerging tools and techniques for data preprocessing, retrieval, and prompt execution, developers can create more effective LLM applications with improved performance and efficiency.
Frequently Asked Questions about LLM Applications
Q1. What are LLMs?
Ans: LLMs (Large Language Models) are a type of language model used in machine learning for natural language processing tasks such as text generation, translation, and sentiment analysis.
Q2. What are some emerging architectures for LLM applications?
Ans: There are various architectures for large language models such as Transformers and GPT (Generative Pre-trained Transformer) models that are commonly used for LLM applications.
Q3. How do LLM applications benefit from in-context learning?
Ans: In-context learning allows LLMs to understand the context in which a word or phrase is used, improving their prompt execution and enhancing the quality of LLM outputs.
Q4. What is fine-tuning in the context of LLMs?
Ans: Fine-tuning refers to the process of adapting a pre-trained LLM model to a specific task or dataset, improving its performance on specific use cases.
Q5. How can I utilize APIs for LLM applications?
Ans: By using APIs (Application Programming Interfaces), you can easily integrate LLM models into your applications for tasks such as text generation, sentiment analysis, and content recommendation.
Q6. What are some common solutions and tools for LLM applications?
Ans: Common solutions include data preprocessing, dataset retrieval, and model evaluation while emerging tools like vector databases and contextual data can facilitate the development and deployment of LLM applications.
Q7. How do emerging architectures for LLM applications impact the industry?
Ans: As new architectures for large language models are developed, the field of AI (Artificial Intelligence) is constantly evolving, leading to advancements in prompt construction and <