
This is a Bot Nirvana Community report on IDP and how it can be used as part of Intelligent Automation. Thanks to contributions from Doug Shannon, David Francis, Amol Rajamane, and Shashi Bhargava
What is it?
Problem: 80% of the business data is trapped in structured, semi-structured, and unstructured forms like emails, images, business documents, and PDF documents.
Solution: Use Artificial Intelligence/ Machine Learning Algorithms (AI/ML) for automated extraction, interpretation, and classification of data from these documents.
Why It Matters – Intelligent Document Processing Benefits

Intelligent Document Processing Benefits include:
- Enables end-to-end automation of workflows
- Improves straight-through processing (STP)
- Improves document processing accuracy (much better than OCR, Template-based solutions)
- Enhanced data quality and usability (Pre/Post Processing, Image Enhancement, Pre-Processing, Thresholding, Resize & Crop)
- Increase in speed for processing large volumes of data
- Quickly assemble documents and reports
- Store and organize documents for easy retrieval or archiving
- Improved Productivity, Cost savings
- Improved Customer Experience
- Improved Compliance and Security
Intelligent Document Processing Use Cases
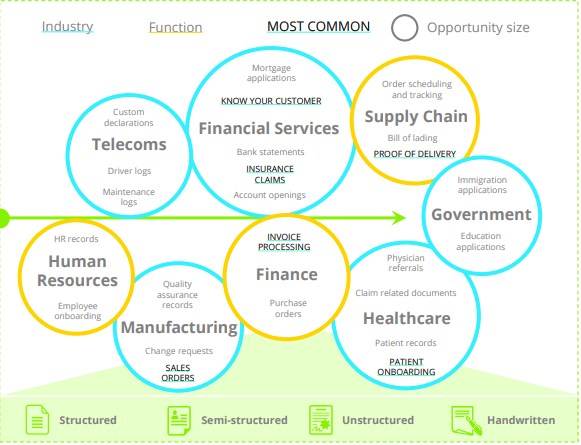
- Finance and Accounting
- Invoice processing
- Collections
- Receipts
- Fraud Detection
- Rebates, Returns
- Tax forms
- Expense Receipts
- Bank Statements
- Human resources
- Employee onboarding
- Resume screening
- Identity documents
- Application processing
- Benefits management
- Procurement
- Purchase orders
- Customer Onboarding
- Vendor Onboarding
- Contract Administration
- Customer contracts
- BFSI Industry
- KYC compliance
- Bank statements
- Checks processing
- Fraud Detection
- Mortgage documents
- Claims management
- Policy administration
- Manufacturing
- Sales Orders Processing
- Process Orders
- SDS
- Data Sheets
- Labels/Packaging
- Custom (Import/Export) Documents
- Certificate of Analysis (COA) documents
- Rebates, Refunds
- Compliance documents
- LEED Letters
- Regulatory documents
- Logistics industry
- Bill of lading
- Shipping label
- Packing list
- Weight tickets
- Certificates
- Proof of Delivery
- Financial services
- Profit and loss statements
- Tax returns
- Income verification
- Healthcare
- Patient Registration
- Patient onboarding
- Patient records
- Processing claims
How It Works
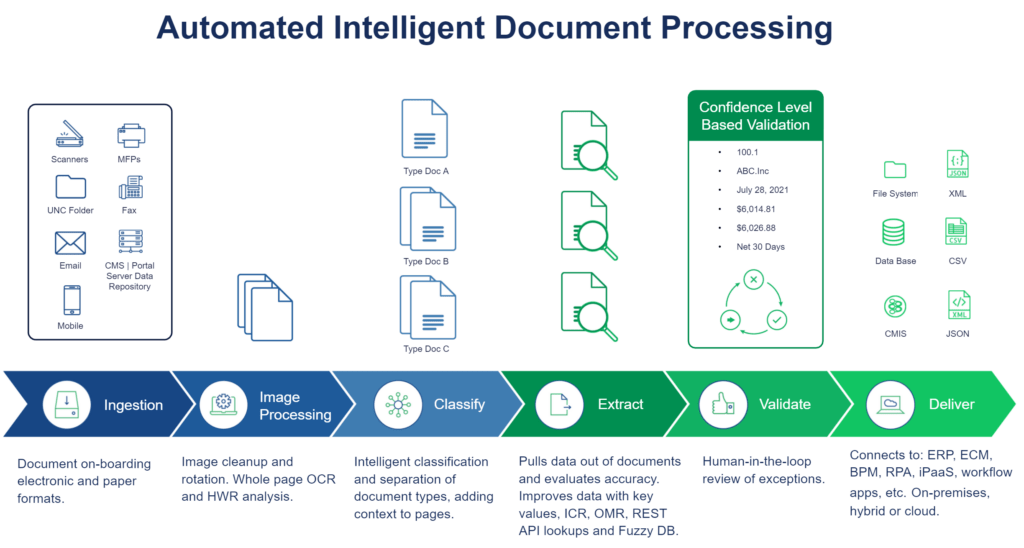
Here is a typical flow for an enterprise-grade IDP solution:
- Document Ingestion: Feed the document in electronic or paper formats.
- Image processing: Process the images to improve image quality.
- Indexing and classification: Classify documents into different document types using text mining and Machine Learning (ML)
- Extract and validate: Extract relevant fields using ML and NLP. The system is trained on samples of documents. Apply pre-defined validation rules to the extracted data to ensure valid data.
- Human-in-the-loop verification: IDP tools provide interfaces for validating the extracted data by people. They review and correct fields that are extracted further improving the ML model.
- Deliver data: The extracted data can be sent to ERP, CRM, and other systems via Intelligent Automation solutions.
Intelligent Document Processing Challenges & Solutions
Current Challenges
- Not having a clear strategy and actionable business goal
- No team (like a CoE) focused on driving the adoption and building toward its use
- Lack of fully built-out IDP solutions. Current “solutions” either do one thing very well or does most things well enough (no 100% reliable solutions)
- A large number of vendors, partners, and stand-alone tools are currently in the IDP space
- Overestimating or underestimating the capabilities of the tool(s)
- Not having Human-in-the-Loop (HITL) at critical steps
- Due to the range of terms used in organizations, the training sets can’t cover the complete spectrum of vocabulary used in a business.
- Poor image quality due to low-resolution scans, different document sizes, and unusual situations like torn pages.
- Handwritten documents are still one of the toughest challenges for most IDP tools
- Completely unstructured documents are still a challenge
- Ensuring the security of data from sensitive documents (e.g. HR documents)
- Integration with upstream and downstream systems is sometimes not easy
- Availability of document extraction-related metadata
- Ready IDP dashboards/reports for operational and business analytics
- Still needs a good quality image (minimum 300dpi)
- Asian Languages support is limited
- NLP Support for unstructured documents, NLP needs special infrastructure
Possible Solutions
- Start with a strong business case that shows the benefits of IDP
- Set realistic expectations on time and costs.
- Ensure the availability of data for training the models.
- Use hybrid ways to extract (a combination of rules, ML models, and people)
- Look for specific solutions. There are a lot of vendors and tools which do a good job at certain things in the IDP process For e.g. Microsoft does well at Invoice extraction, Google does a good job at generic key-value pair extraction.
- Improve the training models by providing use-case-specific data. This is usually not easily available in enterprises.
- Design and ensure that there are Humans-in-the-Loop (HITL) to ensure quality and adaptability
- Add the IDP team to the Digital/Automation CoE and ensure collaboration and alignment with organizational Digital objectives and initiatives.
- Have a clear governance structure.
- Use a Matrix ICR/OCR solution by comparing output from different tools like Amazon Textract, Azure Cognitive, and Google Vision.
- Start first by having your organization start to document the known processes, define the scope, and understand the applications or forms involved. You will have a much higher chance of success
- Ensure data integrity by using access control standards.

“As with any new tool or automation strategy, you need to understand its fit. Is it the “right” tool for the job? Will it provide value or add more complexity to the issue at hand? IDP can be clean, but must be supported. Find the manual, static, and repeated task of bringing on invoices or something simple to begin with. From there you can always add on, however, find that value in the first proof of concept.”
— Doug Shannon, Intelligent Automation Leader
How To Choose The Right IDP Tool
A few measures to consider while evaluating IDP tools:
- Pre-trained AI/ML modules
- Fields Captured
- Key-Value Pair Extraction
- Different Languages
- On-Premise / Cloud Deployment / Mobile SDK
- Table Capture
- Intuitive UI
- Ease of Customization
- 3-Way Matching
- Per page cost
- Transparent Pricing
- Free Trial
- Integrations
- Support, Third-party tools (e.g. tesseract) support
- ML Algorithms
- GCN (Graph Convolutional Networks)
- Visual Features
- Textual Features
- Language Features
- F1 Score (A measure better than Accuracy)

“IDP is not the silver bullet for extraction of data from different digital forms however as this technology matures and we continue to use it in different use cases we can teach the system and learn from the system to build a better tomorrow. It’s important that we work with the machine to improve its skills and ours.”
— David Francis, Smart Automation Architect
Popular Intelligent Document Processing Tools
Standalone platforms
- ABBYY FlexiCapture
- Kofax TotalAgility
- Ephesoft Transact
- Hyland
- Hyperscience
- Rossum
- Datamatics TRucap
- Singularity Systems
- Infrrd
- Parascript
- Docparser
- Indico
- OpenText Intelligent Capture
- Readiris (Canon)
- Nanonets
Automation Platforms
- Automation Anywhere IQ Bot
- UiPath Document Understanding
- WorkFusion
- AntWorks
- Blue Prism Decipher
- Jiffy.ai
Big Tech
System Integrators

“IDP category is quickly catching up as organizations look to extract data from millions of documents automatically with high accuracy using combination of NLP, ML and Rules including self-learning which can be easily configured or trained by business users.”
— Shashi Bhargava, EVP, Datamatics
Technologies And Features Used
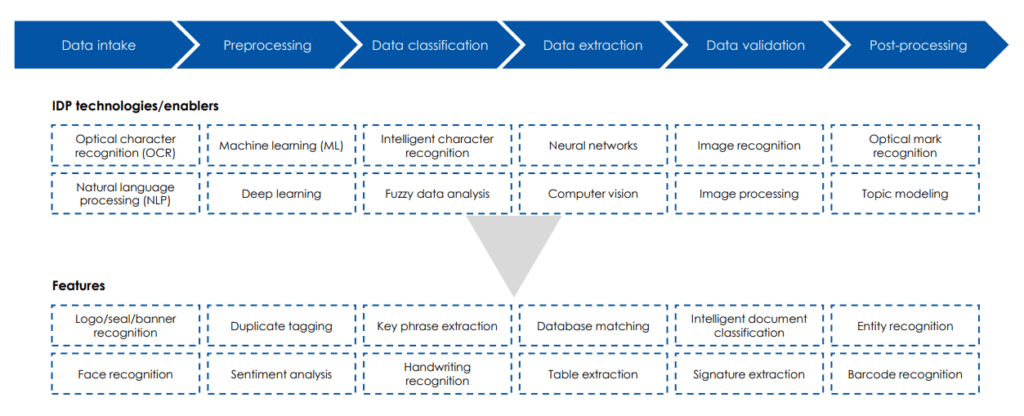
Some of the Technologies used in the current IDP tools:
- Technologies
- Optical Character Recognition (OCR)
- Machine learning (ML)
- Natural Language Processing (NLP)
- Deep learning
- Intelligent Character Recognition (ICR)
- Fuzzy data analysis
- Neural networks
- Computer Vision (CV)
- Image recognition
- Image processing
- Optical mark recognition
- Features
- Handwriting recognition
- Table extraction
- Barcode recognition
- Document classification
- Intelligent language detection
- Scanned PDF detection
- Image baselining
- Intelligent document clustering
- Key phrase extraction
- Label-less extraction
- Sentiment analysis
- Database matching
- Anomaly detection
- Knowledge generation
IDP Trends And Predictions
A few trends and predictions for IDP:
- Extraction of complex data types like audiovisual elements faces from IDs, weather data, engineering drawings, and geospatial data
- Addition of more cognitive capabilities like scanned PDF detection, intelligent document clustering, image baselining, label-less extraction, cognitive searching, anomaly detection, and knowledge generation
- Advanced image recognition and processing capabilities using a combination of computer vision and deep learning algorithms
- Extraction capability for many languages, including Asian, Latin American, and Middle Eastern languages. Increasing demand for multilingual document processing is driving growth in Europe, Asia, and Latin America
- Vertical- and horizontal-specific pre-trained solutions out-of-the-box; app store-like channels for easy access
- Software-as-a-service (SaaS) offerings of the solution to lower the Total Cost of Ownership for enterprises and increase accessibility
- Increased configuration options within the platform to provide greater control to enterprise users
- Enhanced integration with complementary technology solutions, including RPA, Business Process Management (BPM), and Process mining
- Dedicated mobile applications to facilitate document processing through handheld devices
- Availability of benchmarking analytics for particular processes such as invoice processing
- IDP as a service solutions
- A shift from more generic IDP solutions to solutions developed for specific industries and processes
IDP – By The Numbers
- The global market for IDP is estimated at US$700-750 million in 2020, and is expected to grow at a rate of 55-65% over the next year, according to Everest Group. Jul 16, 2021
- KBV Research: The Global Document Processing Market size is expected to reach $4.1 billion by 2027, rising at a market growth of 29.2% CAGR during the forecast period. IDP solutions help in converting unstructured & semi-structured data into structured data which can be used.
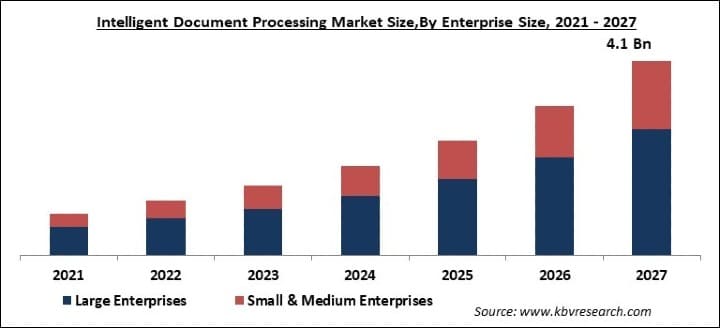
- Gartner: At a $1.2 billion market size in 2020, IDP is an integral technology enabling Hyperautomation in the processing of structured, semi-structured, and unstructured content.
- Accuracy: Most OCR software provides 98 to 99 percent accuracy, measured at the page level. This means that on a page of 1,000 characters, 980 to 990 characters will be accurate. This is not an adequate level of accuracy in data extraction from documents, especially for automation. For instance, in the case of our 1,000-character page, although an OCR engine might have 99 percent accuracy at the page level, it is disastrous if the 10 erroneous characters are within 10 of the 20 data fields required for Automation. So, we need to track field-level accuracy using a field-level confidence score.
What’s The Bottomline?
Intelligent document processing (IDP) has improved the ability to extract and classify data. The accuracy is now between 90 to 99% depending on the type of documents processed. We still do not have complete accuracy and no amount of technological progress will completely solve the document extraction problem. There will always be documents and data fields that fall beyond the system’s capability.
The good news is that you can now combine IDP, Rule-based processing (like RPA), and Human-in-the-loop to extract semi-structured to unstructured data that is vital for many Automation and AI use cases. To ensure success, follow a structured approach knowing your individual needs.