
The emerging application architecture for the Large Language Model (LLM) is a multi-layered structure where each component plays a crucial role in ensuring the effective application of LLMs.
A large function of these frameworks is orchestrating all the various components: LLM providers, Embedding models, vector stores, document loaders, and other tools which we will dive into below.
Here is a view of the emerging LLM App stack (Source A16z)
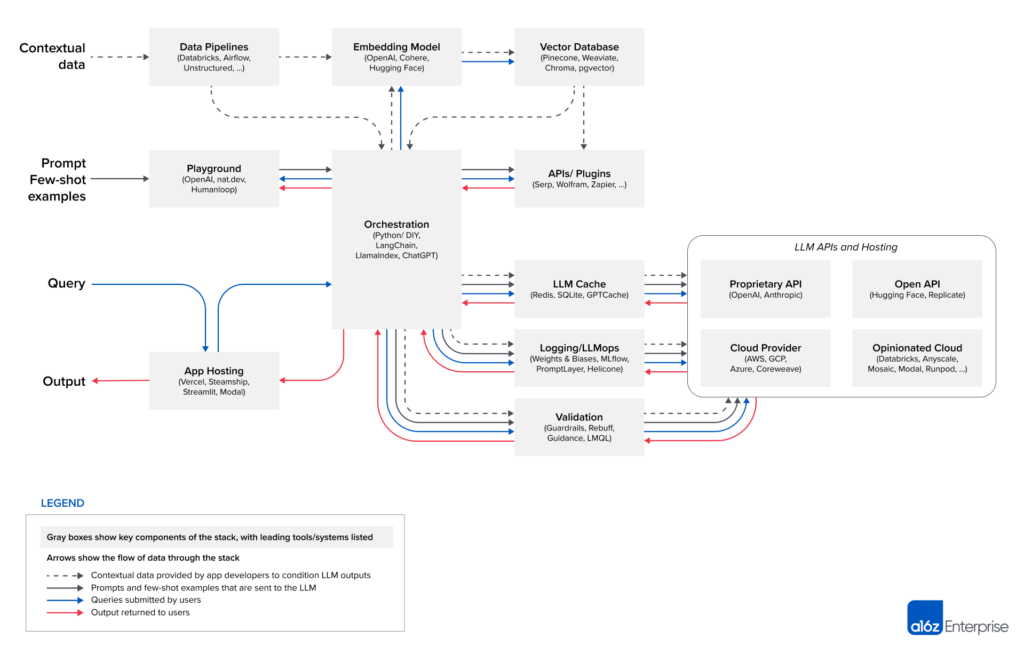
Let’s now slice through each layer of the stack and see what their role is in the LLM application architecture, why we need it, and some tools for the layer:
Data Pipelines
- The backbone of data ingestion and transformation, connecting various data sources including connectors to ingest contextual data wherever it may reside.
- Essential for preparing and channeling data to various components in the LLM application.
- Tools: Databricks, Airflow, Unstructured
Embedding Models
- This component transforms contextual data into a mathematical format, usually vectors.
- Critical for making sense of complex data, enabling easier storage and more efficient computations.
- Tools: OpenAI, Cohere, Hugging Face
Vector Databases
- A specialized database designed to store and manage vector data generated by the embedding model.
- Allows for faster and more efficient querying, essential for LLM applications that require real-time data retrieval like chatbots.
- Tools: Pinecone, Weaviate, ChromaDB, pgvector
Playground
- An environment where you can iterate and test your AI prompts.
- Vital for fine-tuning and testing LLM prompts before they are embedded in the app, ensuring optimal performance.
- Tools: OpenAI, nat.dev, Humanloop
Orchestration
- This layer coordinates the various components and workflows within the application.
- They abstract the details (e.g. prompt chaining; interfacing with external APIs etc.) and maintain memory across multiple LLM calls.
- Tools: Langchain, LlamaIndex, Flowise, Langflow
APIs/Plugins
- Interfaces and extensions that allow the LLM application to interact with external tools and services.
- Enhances functionality and interoperability, enabling the app to tap into additional resources and services.
- Tools: Serp, Wolfram, Zapier
LLM Cache
- A temporary storage area that keeps frequently accessed data readily available.
- Improves application speed and reduces latency, enhancing the user experience.
- Tools: Redis, SQLite, GPTCache
Logging/LLM Ops
- A monitoring and logging component that keeps track of application performance and system health.
- Provides essential oversight for system management, crucial for identifying and resolving issues proactively.
- Tools: Weights & Biases, MLflow, PromptLayer, Helicone
Validation
- Frameworks that enable more effective control of the LLM app outputs.
- Ensures the reliability and integrity of the LLM application, acting as a quality check and taking corrective actions.
- Tools: Guardrails, Rebuff, Microsoft Guidance, LMQL
App Hosting
- The platform where the LLM application is deployed and made accessible to end-users.
- Necessary for scaling the application and managing user access, providing the final piece of the application infrastructure.
- Tools: Vercel, Steamship, Streamlit, Modal
This is an emerging stack and we will see more changes as we progress. We will look to keep this updated as we see big changes.
LLM Application Architecture FAQ
- What are the advantages of using LLMs in application architecture?
- Using LLMs in application architecture can lead to faster development times, improved user experiences, enhanced natural language understanding, and the ability to handle complex language tasks.
- What challenges should developers be aware of when working with LLM app architecture?
- Challenges developers may face when working with LLM application architecture include managing API costs, handling model limitations, ensuring data privacy compliance, and integrating LLMs effectively with existing systems.
- How can developers optimize the performance architecture?
- Yes, LLM application architecture can be used in real-time applications, but developers need to consider factors like API response times, rate limits, and scalability to ensure optimal performance.